TransformerFAM: Feedback attention is working memory
相关链接:arxiv
关键字:Transformer、Feedback Attention Memory (FAM)、working memory、long-context tasks、scaling laws
摘要
TransformerFAM是一种新型的Transformer架构,它通过引入反馈循环机制,使得网络能够关注自身的潜在表示。这种设计促进了Transformer内部工作记忆的出现,使其能够处理无限长的序列。TransformerFAM不需要额外的权重,能够与预训练模型无缝集成。实验表明,TransformerFAM在处理长上下文任务时显著提高了不同模型大小(1B、8B和24B)的性能,展示了赋能大型语言模型(LLMs)处理无限长度序列序列的潜力。
核心方法
- Feedback Attention Memory (FAM): 通过反馈循环,TransformerFAM能够将注意力机制应用于其自身的潜在表示,从而自然地在Transformer中形成工作记忆。
- 无需额外权重: TransformerFAM的设计允许与现有的预训练模型兼容,无需增加额外的权重。
- 工作记忆的假设: 假设1.1中提出,反馈循环中的注意力机制充当工作记忆。
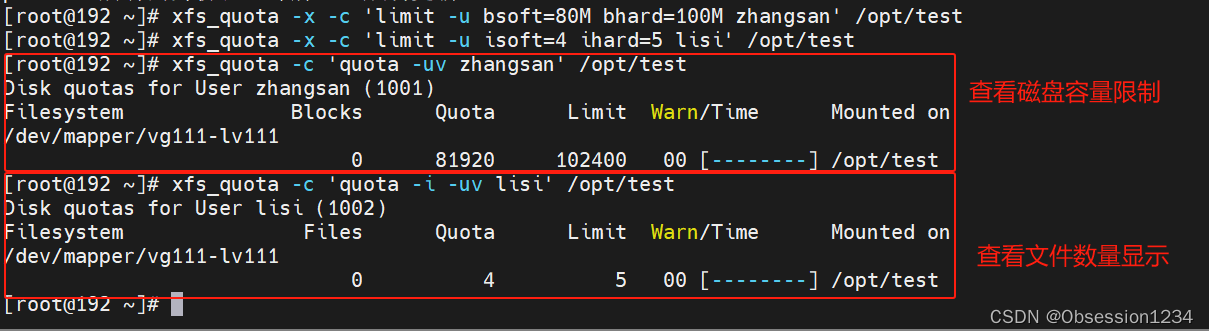
- 块滑动窗口注意力(BSWA): 通过块大小和记忆段的概念,BSWA能够处理长上下文输入,但存在有限的感受野问题。
- 反馈注意力机制: 在BSWA的基础上,TransformerFAM通过反馈机制,使得每个Transformer层都能够拥有分布式的工作记忆,对应其抽象级别。
实验说明
实验结果显示,TransformerFAM在不同模型大小(1B、8B和24B)上处理长上下文任务时的性能均得到显著提升。具体实验数据如下:
| 模型 | BSWA 8B | FAM 8B | BSWA 24B | FAM 24B |
|---|---|---|---|---|
| Isabelle | 82.1 | 82.5 | 86.6 | 86.6 |
| NarrativeQA | 18.4 | 19.3 | 22.6 | 23.0 |
| PG-19 | 52.4 | 52.9 | 55.7 | 57.2 |
| ScrollsQasper | 12.4 | 18.5 | 28.0 | 29.4 |
| ScrollsQuality | 47.3 | 48.5 | 55.4 | 58.0 |
| XLSum | 22.0 | 24.7 | 24.7 | 26.4 |
数据来源于论文中提到的Flan-PaLM模型,使用256k的sentencepiece tokenizer进行处理。实验结果表明,TransformerFAM在所有长上下文任务上均优于TransformerBSWA,且随着模型大小的增加,TransformerFAM的可扩展性得到了验证。
结论
TransformerFAM通过引入反馈注意力机制,有效地解决了大型语言模型在处理长序列时的工作记忆问题。这种架构不仅能够处理无限长度的输入序列,而且在不同规模的模型上都显示出了优越的性能。此外,TransformerFAM的设计允许与现有的预训练模型无缝集成,无需额外的权重,为未来的研究和应用提供了新的可能性。